前の記事でDavinci ResolveにReactorを導入してみました。
今回は導入したReactorの機能を使って、音声ファイルであるwavファイルの波形に合わせてキャラクターを口パクさせてみた記事になります。
若干変更点などはありますが、基本的には参考資料に挙げている動画様の内容と同じになるので詳細はそちらを参照してください。
では、始めます。
0:素材の準備
素材としてキャラクターの絵と口パクする差分の絵、そしてwavファイルが必要となります。
今回はキャラクターの素材例として以下のものを準備しました。
・00_base.png

・01_paku.png
![]()
音声ファイルはwav形式であれば何でもよいですが、過去にOpenJTalkで合成音声を作った記事を書いているのでそれで準備しました。
素材を準備するのが面倒な場合は、以下にzipファイルとしてまとめているのでダウンロードして使ってください。
以降は上記素材を使うという前提で進めます。
1:ReactorのSuck Less Audioを有効にする
まずは今回wavファイルの波形に連動させるのに必要なReactorのSuck Less Audioを有効にします。
Davinci Resolveを起動させて空のプロジェクトを開き、上部メニューの「ワークスペース」→「スクリプト」→「Comp」→「Reactor」→「Open Reactor」を選択します。
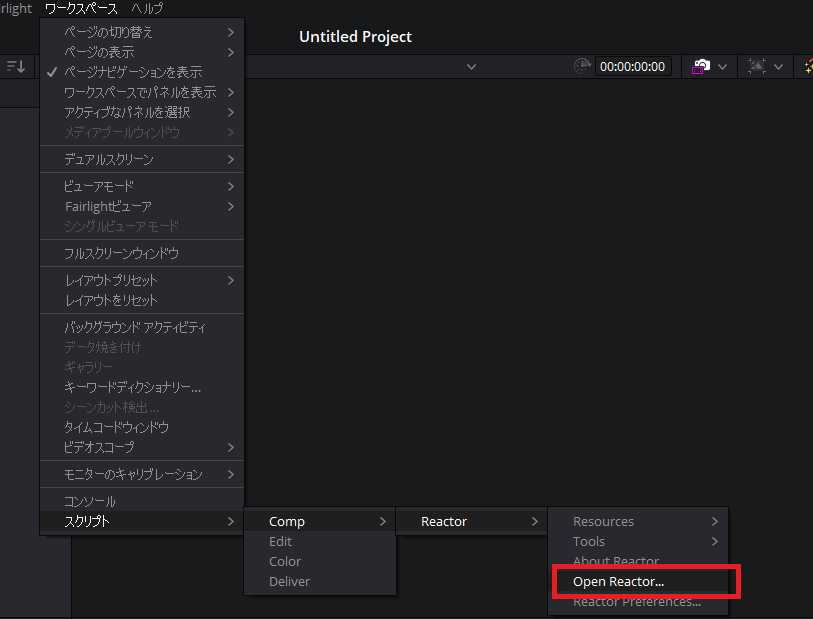
少しロード画面が出るので待った後、以下のような画面が表示されるので、左側の「Modifiers」をクリックして出てきた中の「Suck Less Audio」にチェックを入れてインストールします。
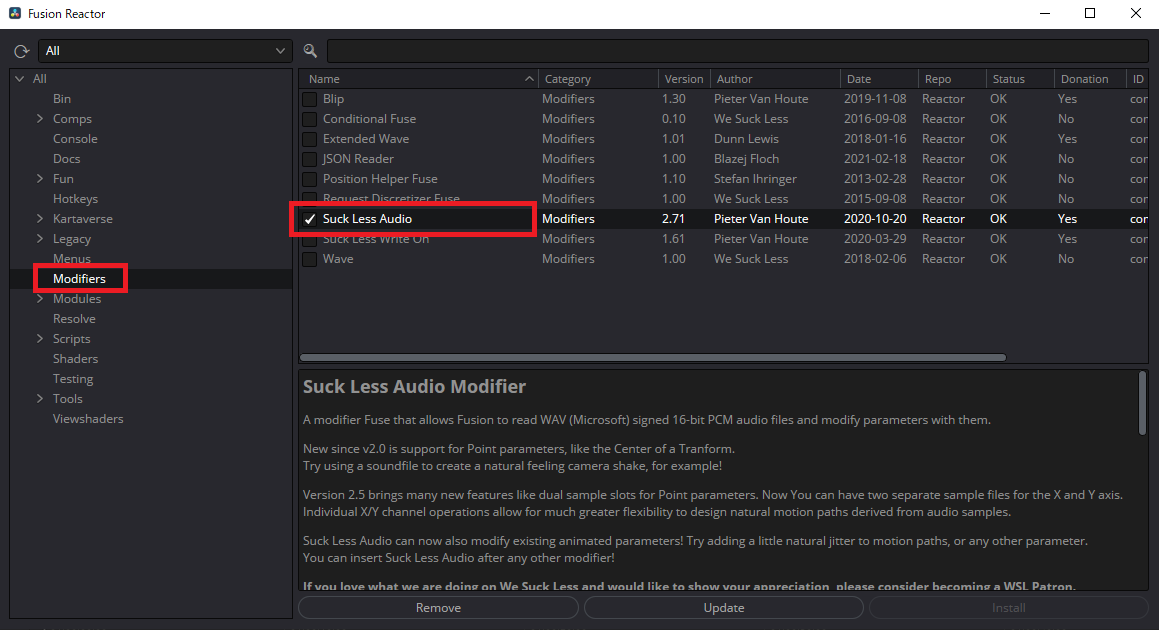
これでSuck Less Audioが使えるようになります。
2:タイムラインに素材を配置する
最初に0の素材を「全角が入っていない」パスに移動させます。パスに全角を入れないのは、Suck Less Audioを使う場合に全角が入っていると上手く動かない場合があるためです。
今回はCドライブ直下に「paku_sozai」というフォルダを作成してその中に各種必要な素材を入れています。
素材の配置ができたら、Davinci Resolveのメディア欄にドラッグ&ドロップで素材を読み込ませます。
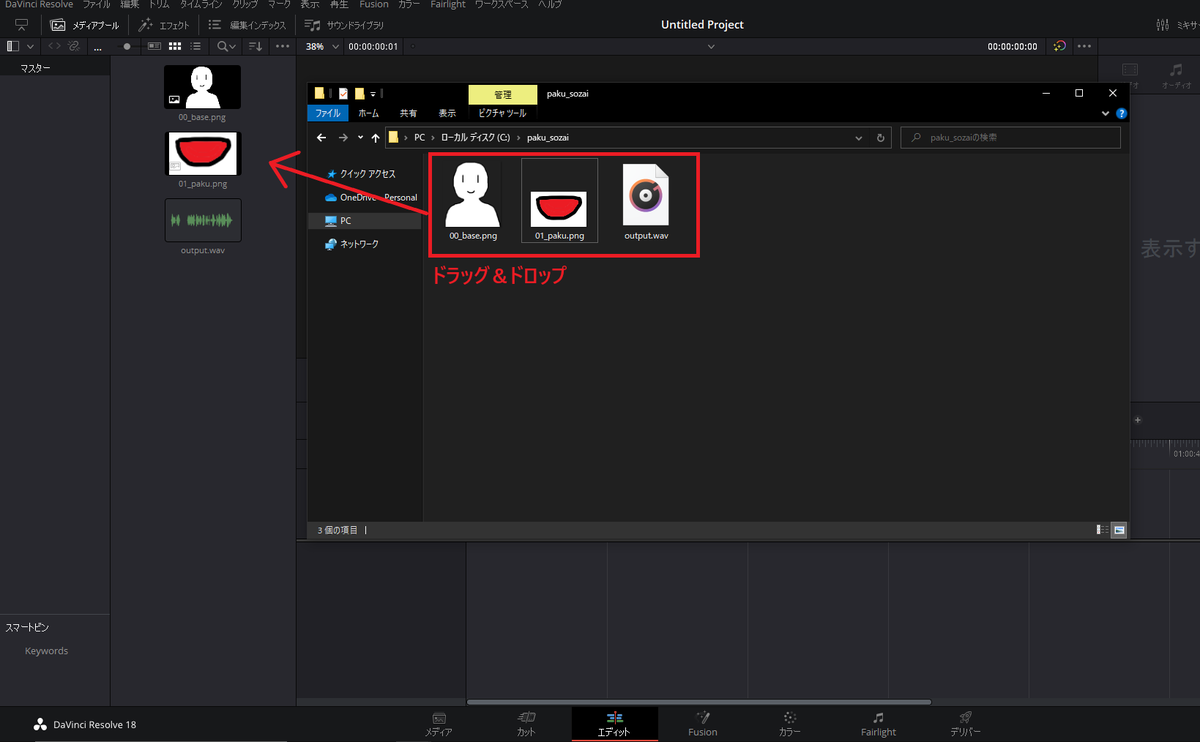
読み込みができたら「エディット」画面を開いて「00_base.png」をタイムラインにドラッグ&ドロップします。
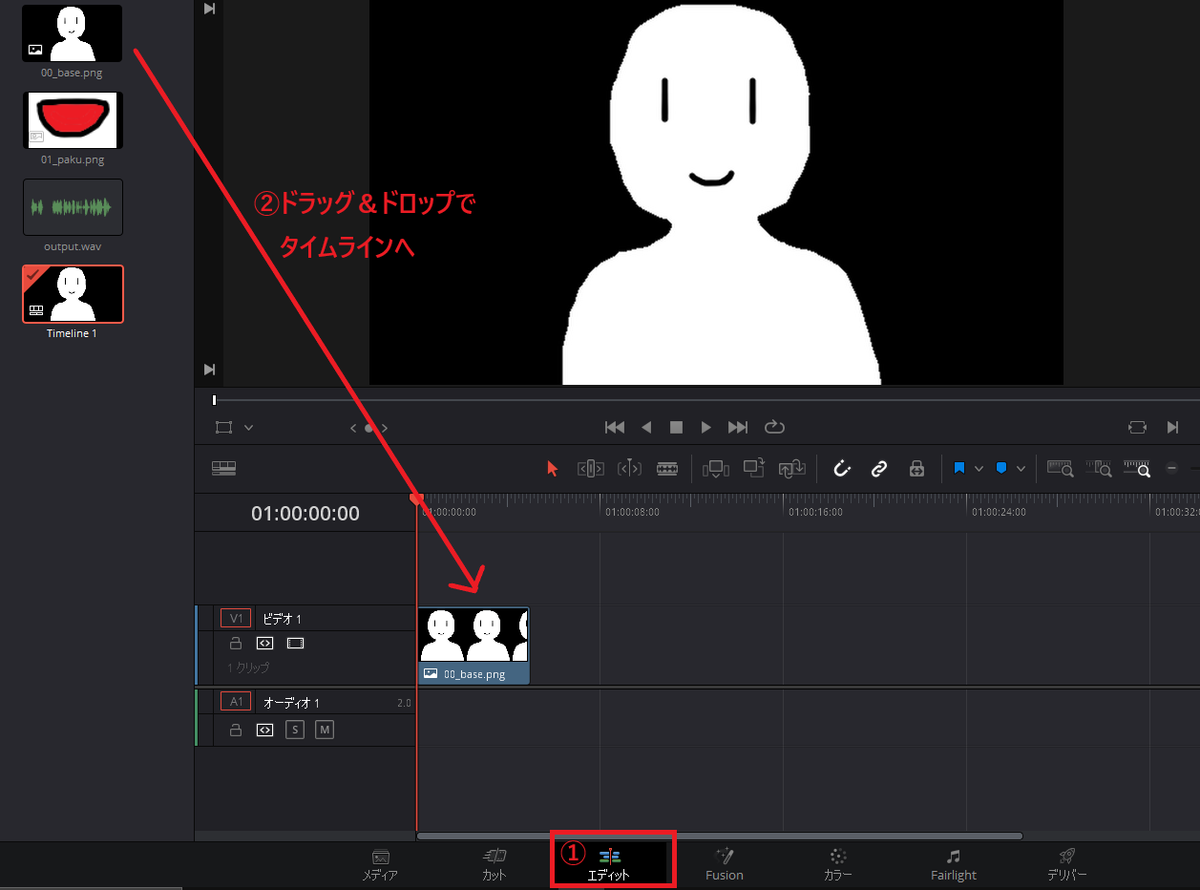
次に音声ファイルもタイムラインにドラッグ&ドロップし、画像の端をドラッグして音声の長さと同じ表示時間になるよう調節します。
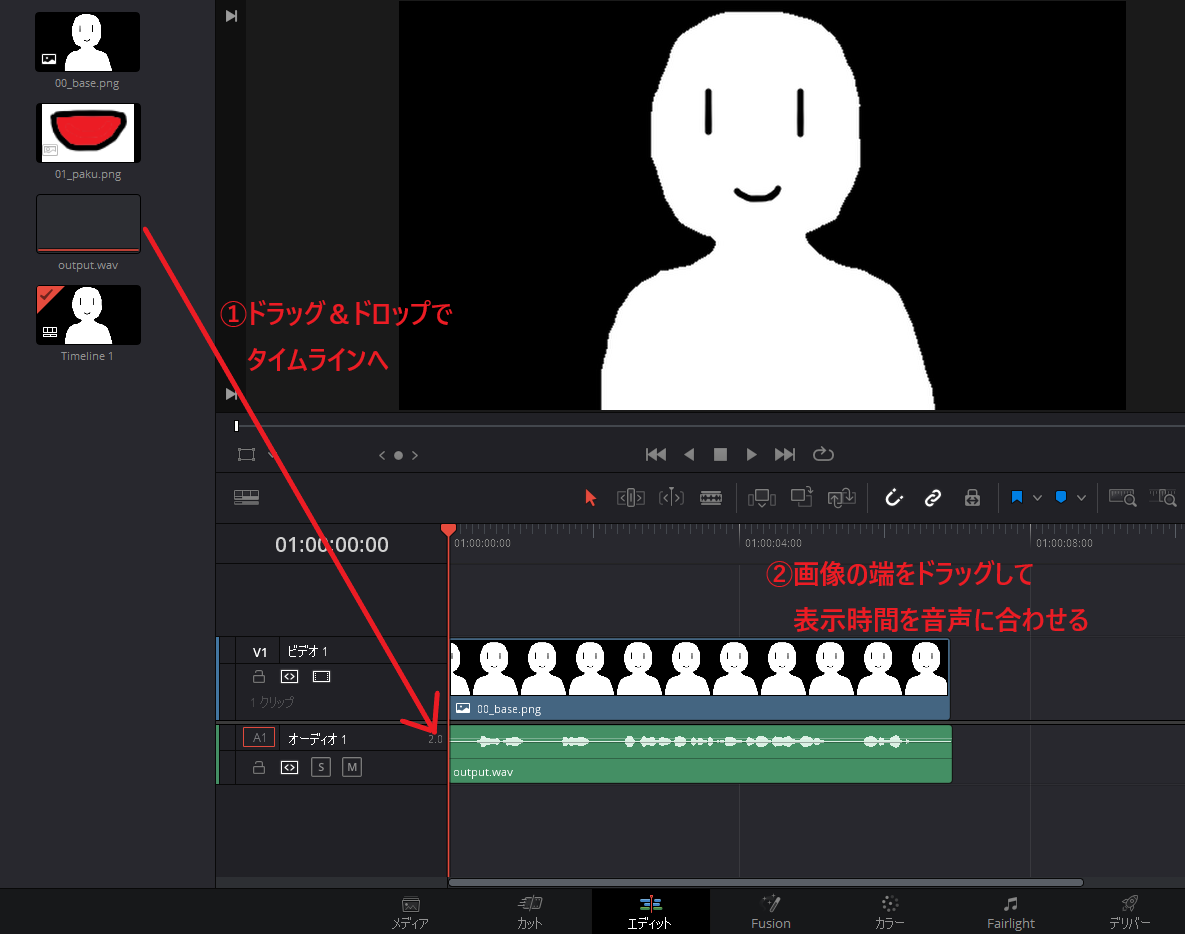
この状態で再生させると、ただ画像が表示され音声が流れているだけです。
実際に口パクをさせるためにFusionを使っていきます。
3:Fusionを使って口パクをさせる
2までできたらタイムラインにある「00_base.png」を選択した状態で右クリックをし、出てきた中にある「Fusionページで開く」をクリックします。
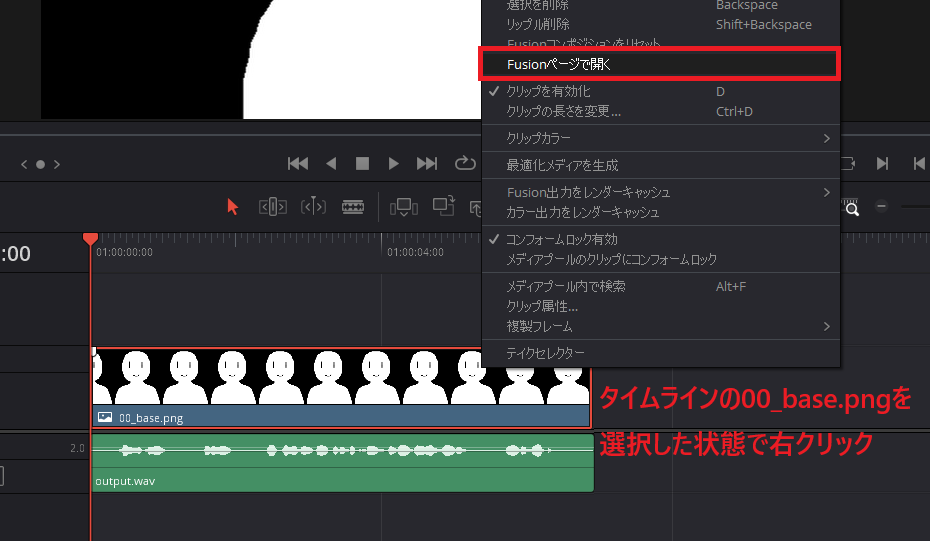
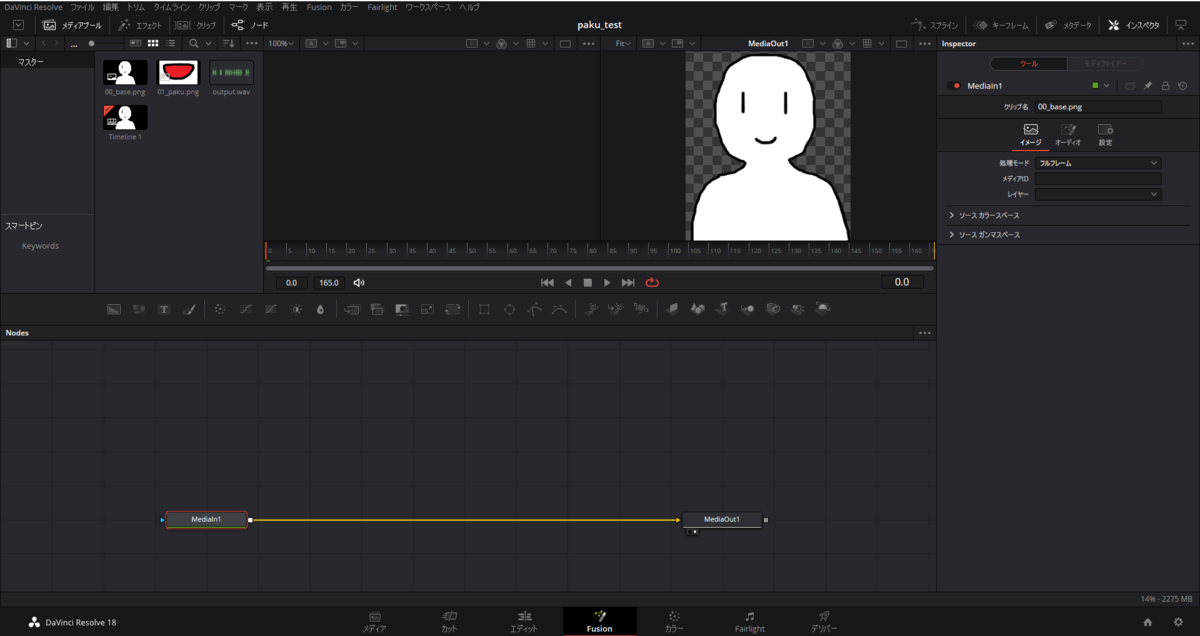
Fusionページになります。
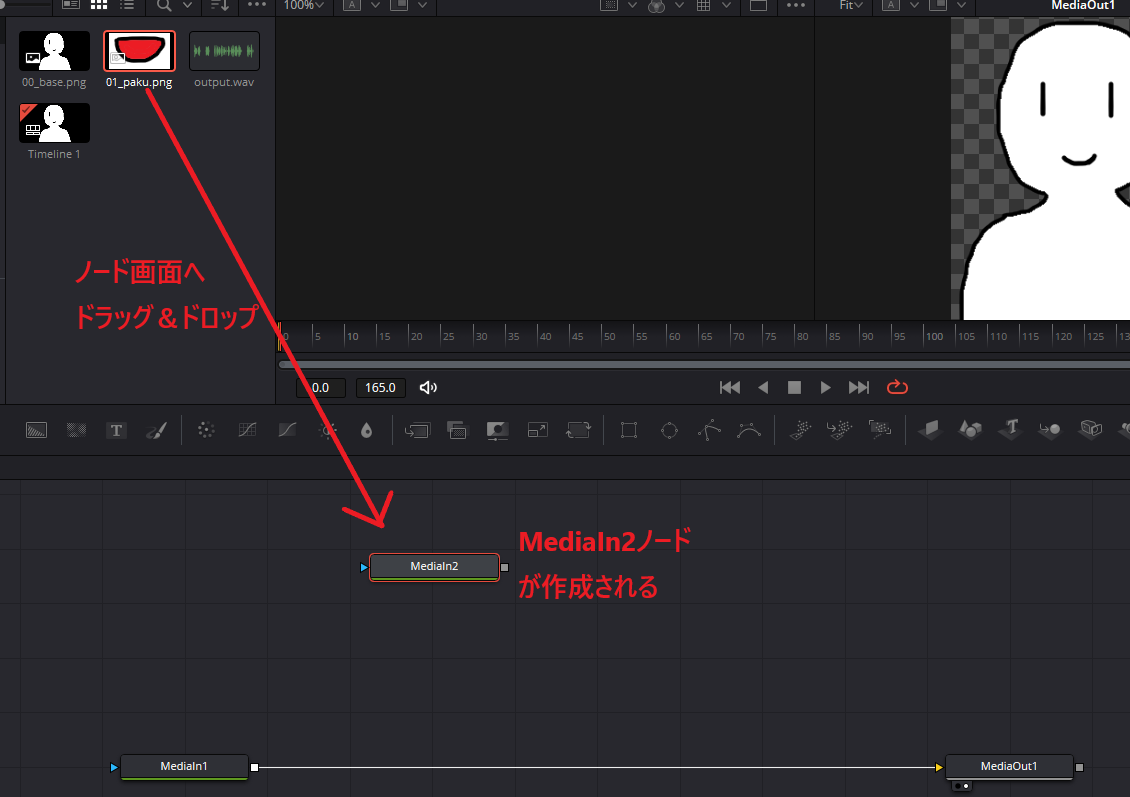
メディア欄にある「01_paku.png」をノード画面にドラッグ&ドロップすることで「MediaIn2」というノードが作成されます。
ノード画面の上にある「変形」をドラッグ&ドロップして「Transform」ノードを追加します。
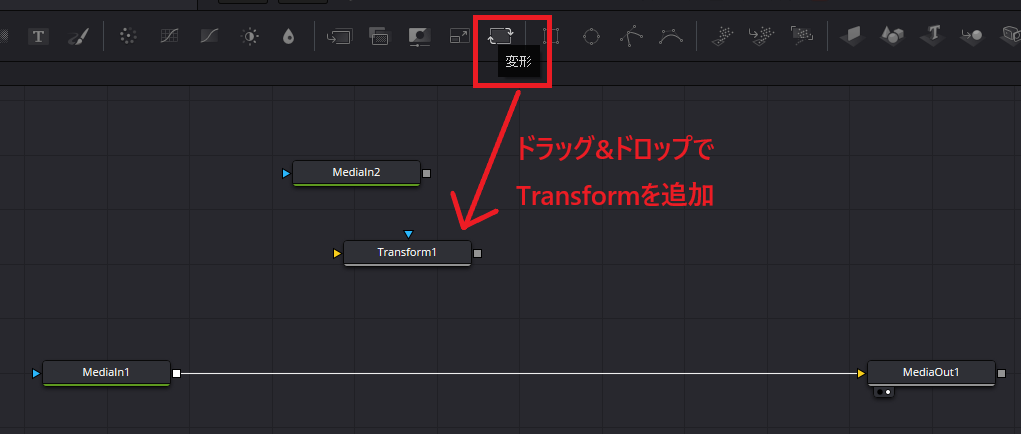
Transformノードが追加できたら、以下のようにノードを繋げてMediaIn1とTransformの結果をMergeノードでマージします。
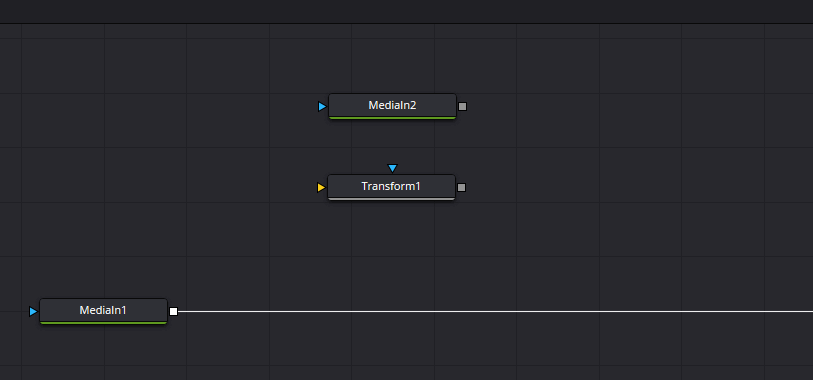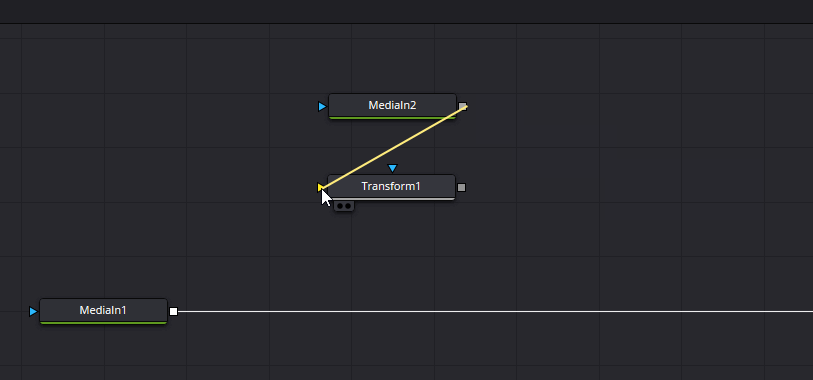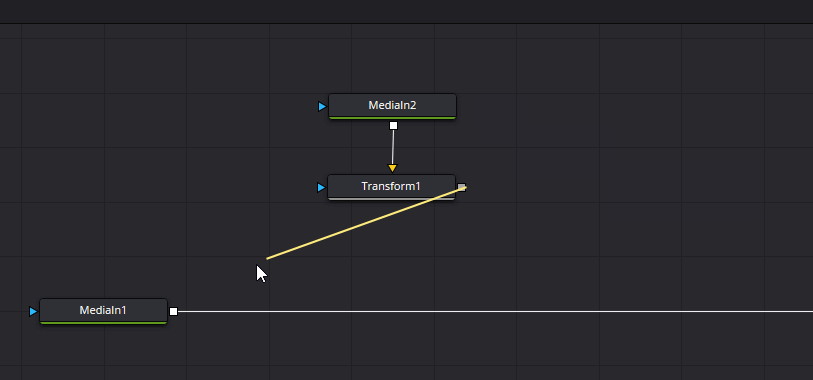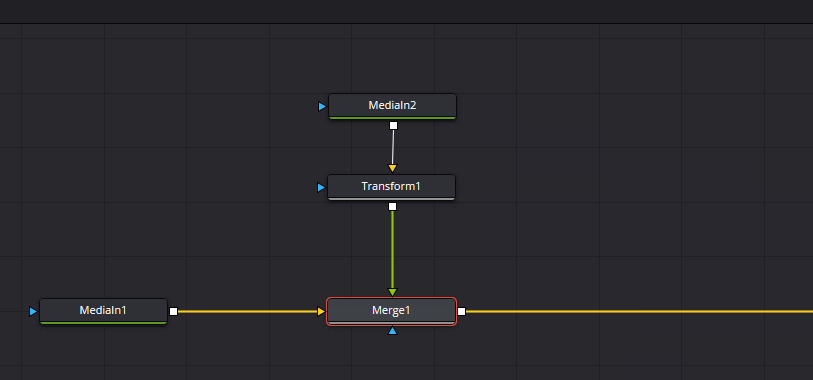
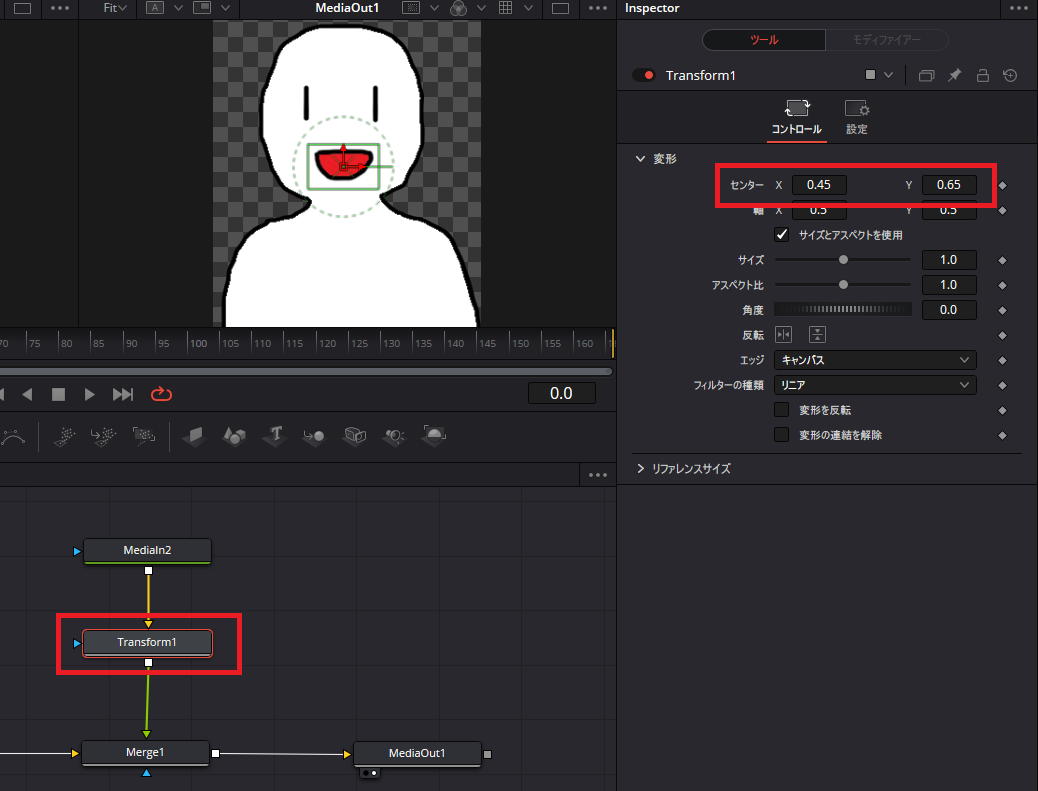
マージするとMediaOutの結果として00_base.pngの画像に01_paku.pngの画像が上乗せされた状態になるので、「Transform」ノードを選択した状態でセンターの「X」、「Y」の値を調節してちょうどいい位置に開口が来るように調節します。今回はXを0.45、Yを0.65にしました。
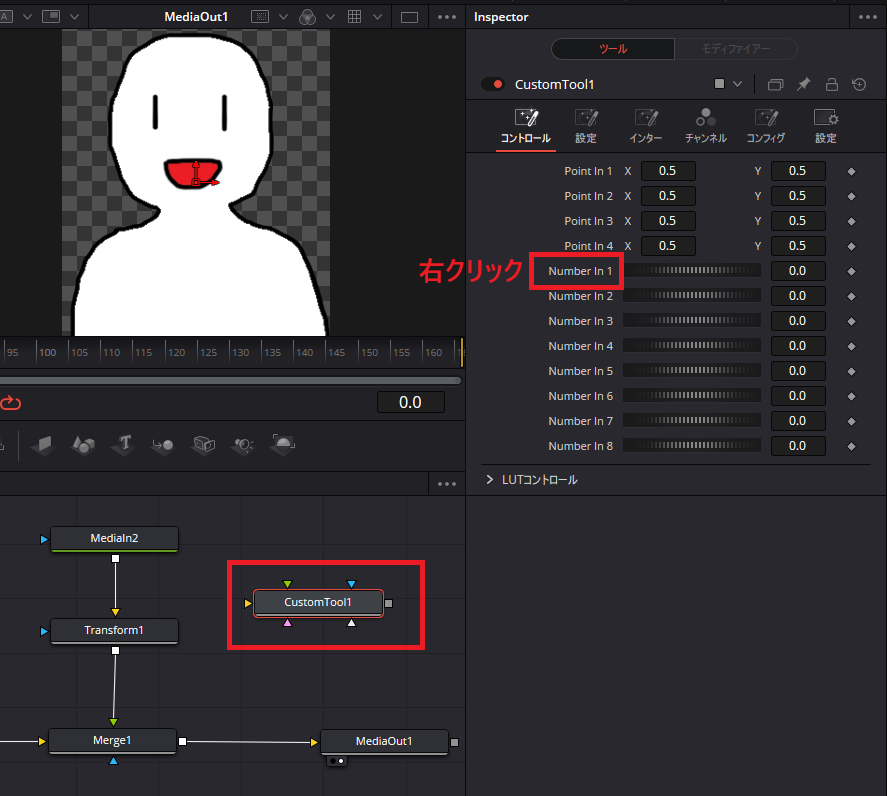
次にノード画面で「Shift + Space」キーを押下して出てきた検索の入力欄に「カスタムツール」と入力して出てきたものを選択し、「追加」ボタンを押下します。

「Custom Tool」ノードが追加されるので、それを選択した状態で出てくる「Number In 1」を右クリックします。
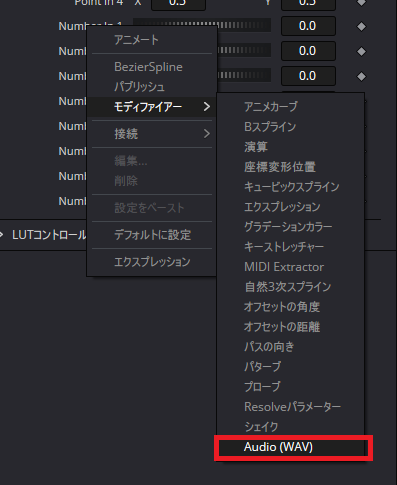
右クリックして出てきたメニューから「モディファイアー」→「Audio(WAV)」を選択します(※「Audio(WAV)」が出てこない場合は1の手順を行ってください)。
選択後、上部にある「モディファイアー」をクリックし出てきた中の「ブラウズ」ボタンをクリックして口パクさせたいwavファイル(2でタイムラインに読み込ませた音声ファイルと同じもの)を選択します。
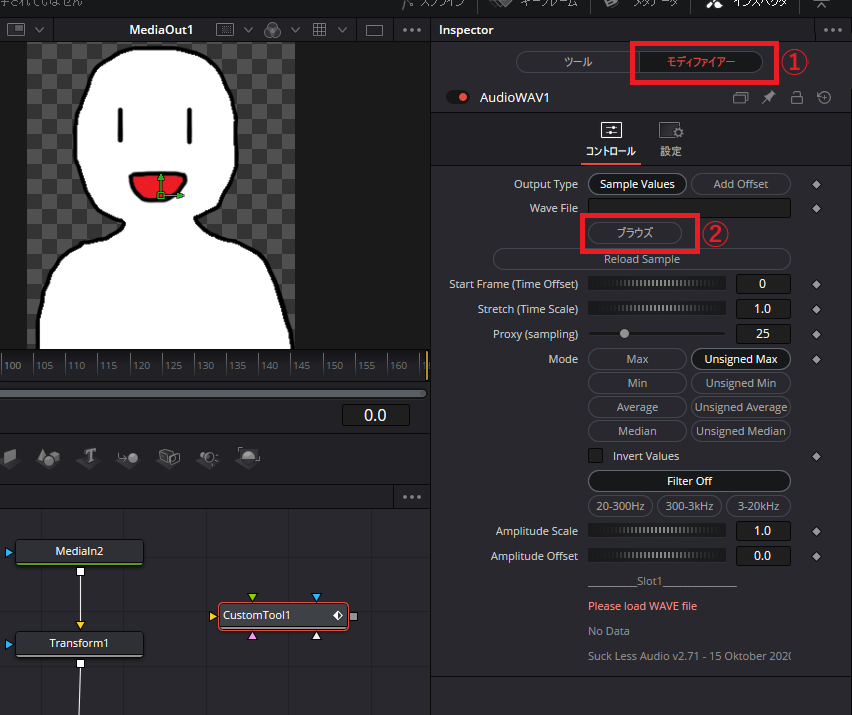
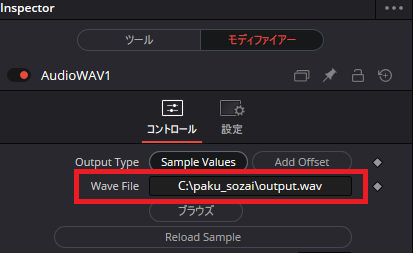
音声ファイル読み込み後、ファイルパスが表示されます。
この状態で「ツール」の画面に戻って再生してみると、Number In 1の値が音声に合わせて細かく動くようになっています。
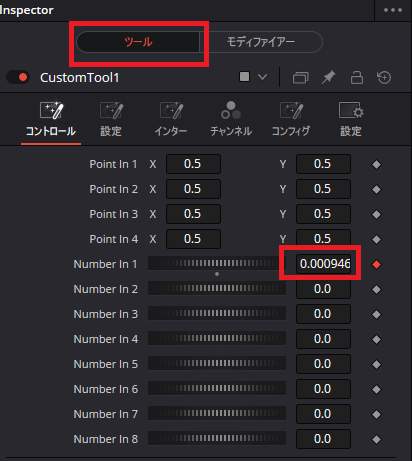
あとはこの「Number In 1」の値を使って口パクの画像を表示させたりさせなかったりするだけです。
そのためにスクリプトを使います。
Mergeノードを選択した状態で「設定」をクリックします。その中に「フレームレンダースクリプト」と「開始レンダースクリプト」という項目があるのでその中にスクリプトを記述していきます。
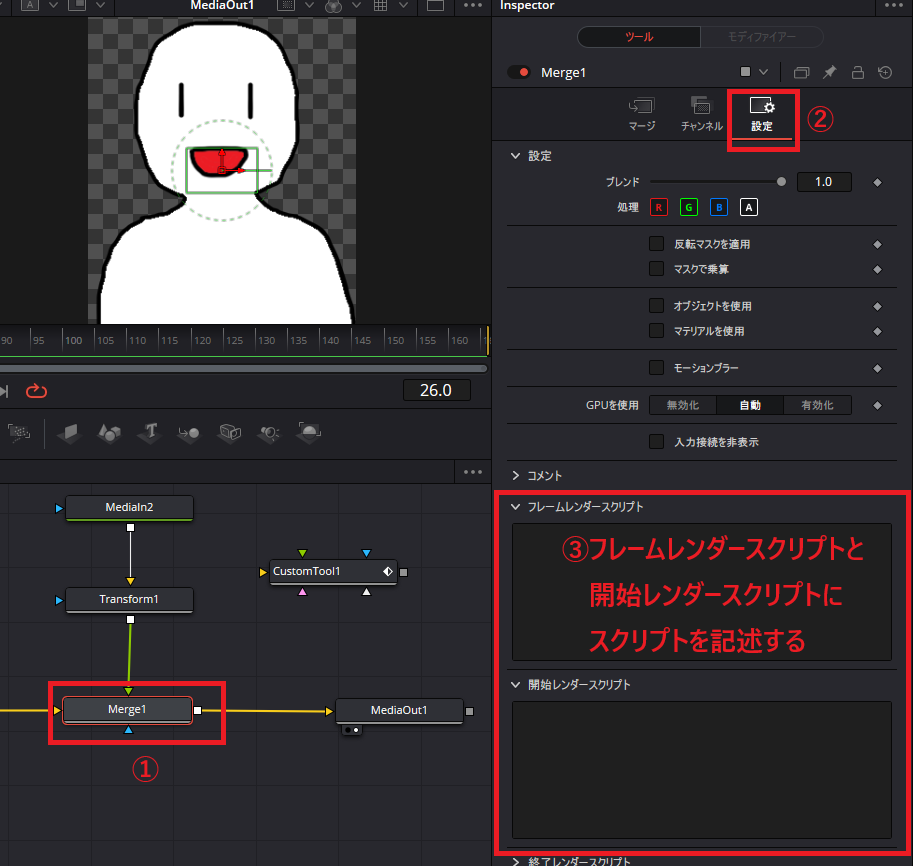
記述するスクリプトの内容は以下の通りです。
・フレームレンダースクリプト
if CustomTool1.NumberIn1 >= AudioVolume then self.Size = MouthSize else self.Size = 0 end
・開始レンダースクリプト
AudioVolume=0.17 MouthSize=1
「AudioVolume=0.17」の値が口を閉じるか開けるかの閾値になっているので、音声ファイルによってこの値を調整する必要があります。
実際にMergeノードにこのスクリプトを記述して再生すると、以下のように音声に合わせて口パクするようになります。
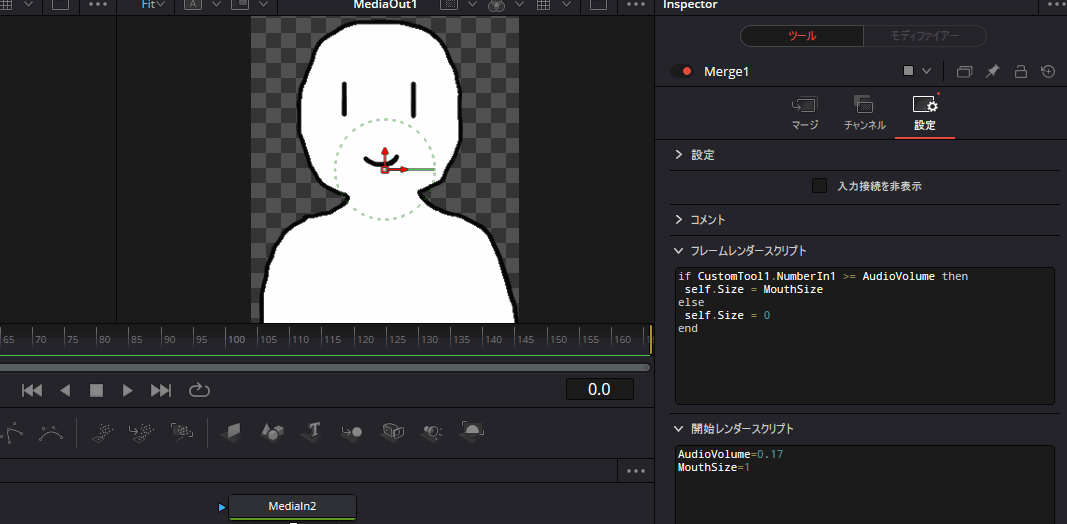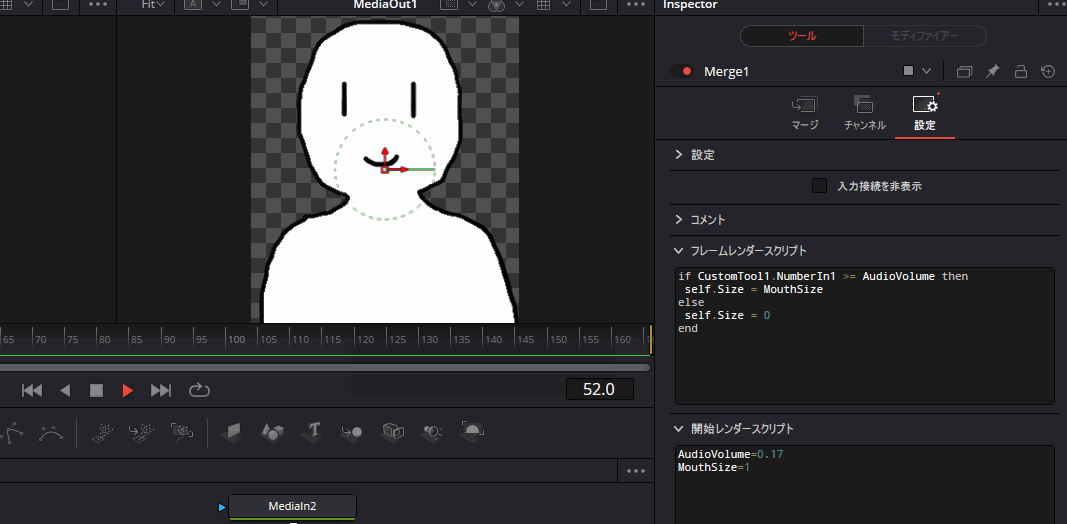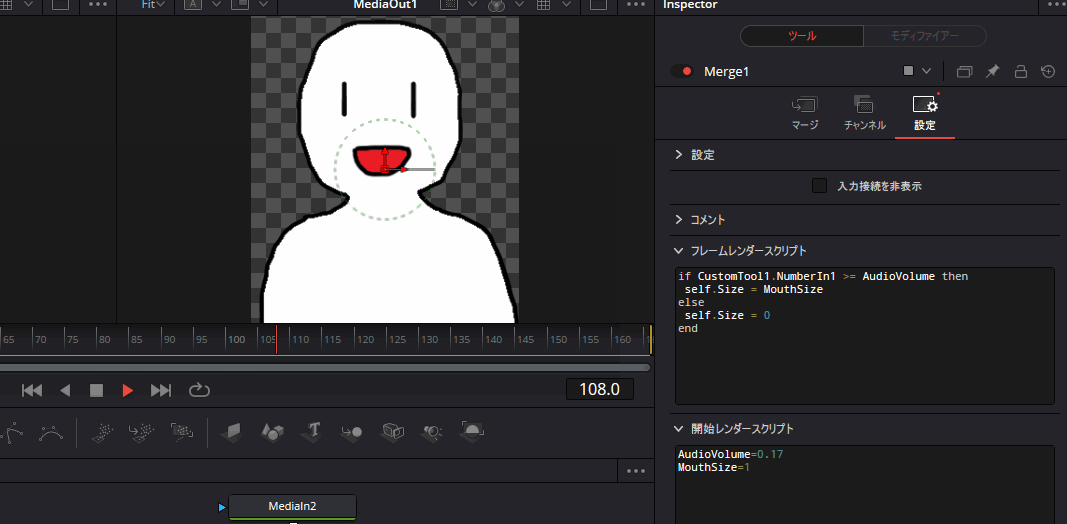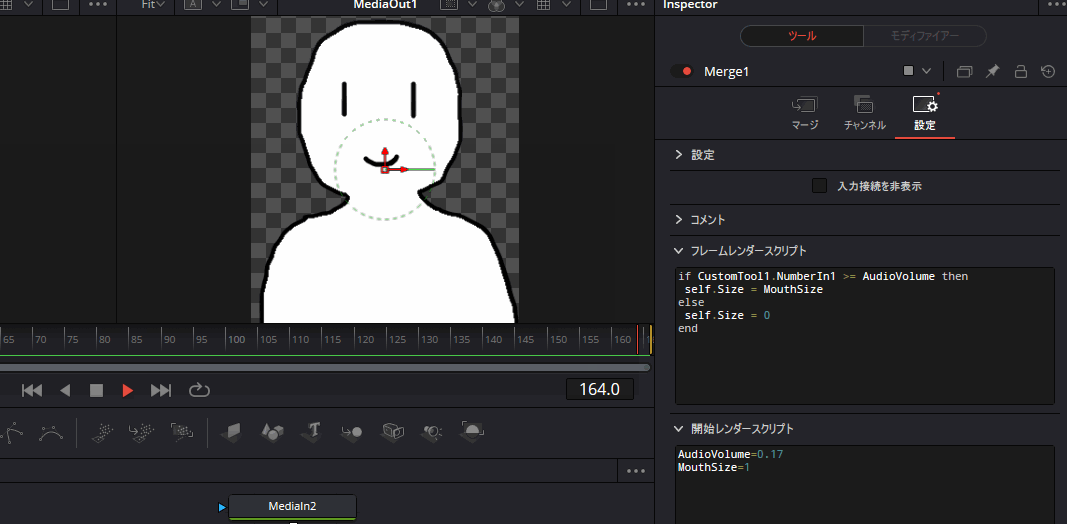
あとはいつも通りデリバー画面から動画として書き出せばよいだけです。
実際に出力してみた動画が以下になります。
以上がDavinci Resolveでwavファイルに合わせて口パクさせる方法になります。
また余談ですが、今回は画像に対してFusionを使って口パクさせているのでエディット画面からキャラクターの位置を変更させたり変形させたり背景を追加したりなどもできます。
つまり、よく目にするゆっくり解説などの動画もこの手法を使えば作成可能だと思うので、割と使い道は多そうです。
・参考資料